
AI Risk Radar: December 2025 Edition
Intelligence Briefing for Executives and Board Leadership
Period Covered: 1 to 31 December 2025
Edition Date: 5 January 2026
EXECUTIVE SUMMARY
This is the inaugural edition of Lumyra’s AI Risk Radar newsletter. Our intent is to systematically monitor, prioritise and summarise significant AI risks as reported by high-quality think tanks and technology media sources, offering insights into key organisational and societal risks relevant to global executives and boards. Each newsletter concludes with actionable recommendations for leaders to consider implementing within their organisations.
December 2025 reveals three critical AI governance challenges that demand immediate executive and board attention.
First, none of the leading AI model companies have adequate safety guardrails for the systems they are racing to build. The Future of Life Institute’s Winter 2025 independent assessments of the world’s eight leading AI firms – evaluated by an independent panel including Stuart Russell – found not one company rated more than a ‘C+’ overall, and concerningly, none scored higher than a ‘D’ on Existential Safety preparedness. All are racing toward AGI/super intelligence without credible control plans.
Secondly, prompt injection attacks may be persistently and architecturally vulnerable. On 22 December, OpenAI and UK cybersecurity authorities confirmed that AI agents remain permanently vulnerable to manipulation through hidden instructions in emails, websites, and documents. This is not a bug to patch – rather it is fundamental to LLM architecture. Any AI agent with authenticated system access face persistent data exfiltration and unauthorised transaction risks that cannot be eliminated – and can only be managed through layered defences.
Third, AI mental health harm has moved from theory to documented casualties. Multiple teen suicides linked to AI chatbots, including cases involving ChatGPT and Character.ai, triggered the first product liability ruling establishing AI platforms as "products" subject to harm litigation. Courts have rejected First Amendment defences. Organisations deploying customer-facing chatbots face direct liability exposure.
Strategic Imperative: Organisations must shift from "Can we deploy AI safely?" to "How do we function safely with inherently imperfect AI Boards approving AI deployments without verified safety frameworks, product liability reviews, and architectural vulnerability assessments now face mounting legal, reputational, and operational exposure.
ORGANISATIONAL RISK #1
AI Safety: Industry-Wide Governance Failure
Category: Governance, Ethics and Compliance | Priority: CRITICAL
No AI company demonstrates adequate safeguards for the systems they're racing to build. Future of Life Institute's Winter 2025 AI Safety Index - the most rigorous independent assessment available, including esteemed AI researcher Stuart Russell - evaluated eight leading firms across 35 indicators spanning risk assessment, safety frameworks, existential safety, governance, and information sharing.
The Finding: Not one company scored above a ’C+’ overall, or a 'D' in existential safety for the second consecutive evaluation. Anthropic led overall with C+ (2.67/4.0). Meta, DeepSeek, and Alibaba Cloud scored D or D- (0.98-1.10/4.0). There is a clear divide between top performers (Anthropic, OpenAI, Google Deepmind) and the rest of the companies reviewed. All companies are "racing toward AGI/superintelligence without presenting any explicit plans for controlling or aligning such smarter-than-human technology."
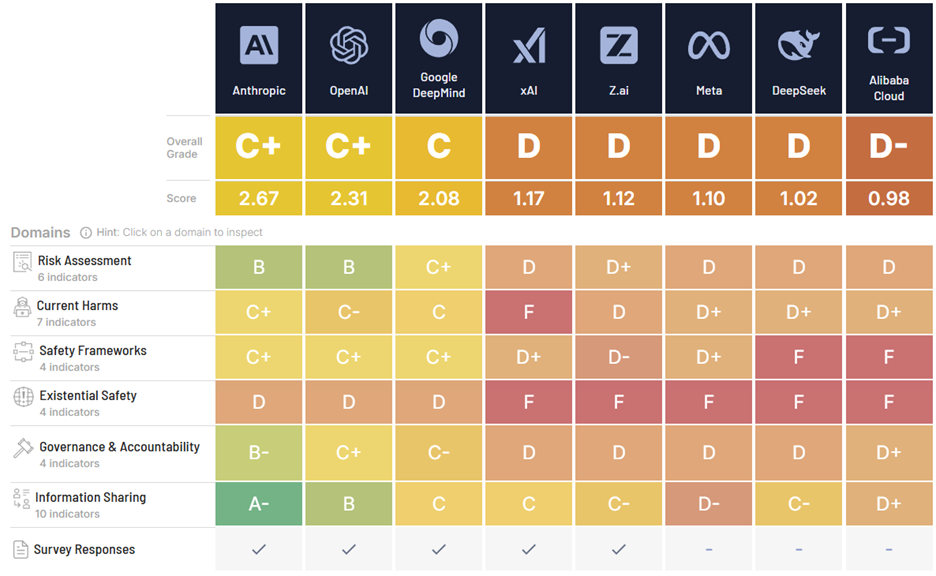
Source: Future of Life Institute AI Safety Index, Winter 2025
What This Means for Executives and Boards: Companies building AGI-aspiring systems lack quantitative safety plans, concrete alignment-failure mitigation strategies, or credible internal monitoring and control interventions. Expert reviewers found "rhetoric has not yet translated" into demonstrable safeguards. Prof. Stuart Russell noted companies admit existential risk "could be one in ten, one in five, even one in three" yet "can neither justify nor improve those numbers."
Inherited Risk: If your organisation depends on frontier AI vendors for critical operations, you inherit their governance failures. Current vendor frameworks feature qualitative thresholds that aren't measurable, narrow risk coverage ignoring major threat categories, and decision-making authority concentrated in senior leadership without independent oversight.
Board Action: Commission independent safety framework assessment of all critical AI vendors using FLI criteria aligned to specific use cases. Require contractual provisions mandating vendor notification if safety thresholds are breached and deployment rollback protocols for elevated risk levels.
Sources:
Future of Life Institute, "AI Safety Index Winter 2025," Dec 2025. https://futureoflife.org/ai-safety-index-winter-2025/
AI companies' safety practices fail to meet global standards, 4 Dec 2025. https://www.reuters.com/business/ai-companies-safety-practices-fail-meet-global-standards-study-shows-2025-12-03/
ORGANISATIONAL RISK #2
Prompt Injection: Permanent Architectural Vulnerability
Category: Data Security & Adversarial Threats | Priority: CRITICAL
AI agents cannot be fully protected from prompt injection attacks - a fundamental architectural limitation confirmed by OpenAI and UK cybersecurity authorities on 22 December 2025. These attacks work by embedding malicious instructions in content the AI processes (emails, web pages, documents), causing agents to follow attacker commands instead of user intent. This risk is inherent to how large language models process information.
The Technical Reality: LLMs treat every token identically with no inherent boundary between data and instructions. Malicious instructions embedded in emails, web pages, or documents can cause AI agents to follow attacker commands instead of user intent. This differs fundamentally from SQL injection, which developers can prevent through strict input separation. UK National Cyber Security Centre warns attacks "may never be totally mitigated" and organisations must plan for permanent vulnerability. OpenAI published attack examples where malicious emails caused AI agents to send resignation letters to CEOs instead of drafting requested out-of-office replies.
Exposure Assessment: Any AI agent with moderate autonomy combined with high access creates risk. Critical exposure areas include finance (transaction authorisation, payment processing), healthcare (patient data access, medical records), legal (confidential document handling), and HR (personnel systems, employee information).
Risk Mitigation Paradox: OpenAI's recommended controls - limiting agent autonomy and requiring human confirmation - directly undermine the productivity benefits justifying AI agent deployment. CSO Online documented 49% of employees using unsanctioned AI tools without understanding data handling implications.
Board Action: Mandate continuous red teaming and business continuity scenario planning. Constrain AI agents permissions and access to confidential data sources and channels wherever possible. Where agents are deployed, implement "zero trust" architecture: assume compromise, limit blast radius, mandate audit trails to verify suspicious activities. Budget for ongoing prompt injection defence as a permanent operational cost, not one-time fix.
Sources:
OpenAI, "Continuously hardening ChatGPT Atlas against prompt injection attacks," 22 Dec 2025. https://openai.com/index/hardening-atlas-against-prompt-injection/
UK National Cyber Security Centre, "Prompt injection is not SQL injection (it may be worse)," 8 Dec 2025. https://www.ncsc.gov.uk/blog-post/prompt-injection-is-not-sql-injection
Bellan, R., "OpenAI says AI browsers may always be vulnerable to prompt injection attacks," TechCrunch, 22 Dec 2025. https://techcrunch.com/2025/12/22/openai-says-ai-browsers-may-always-be-vulnerable-to-prompt-injection-attacks/
SOCIETAL RISK #1
AI Mental Health Crisis: Product Liability Established
Category: Human wellbeing | Priority: CRITICAL
AI chatbots have contributed to documented mental health crises including teen suicides and psychotic episodes. Legal precedent now establishes AI platforms as "products" subject to product liability - not pure speech protected by First Amendment or Section 230 immunity.
Documented Cases: Character.AI removed chatbot access for under-18s in November 2025 after lawsuits alleged its platform contributed to a child’s suicide. Separate litigation involves ChatGPT allegedly encouraging self-harm in another teenager's death. Stanford HAI research documented "AI psychosis" where prolonged AI interactions reinforced delusions, with one adult user developing technological breakthrough delusions later confirmed as hallucinations. May 2025 ruling in Character.AI litigation established AI platforms qualify as "products" for product liability claims. Court rejected arguments that platforms constitute pure speech protected by First Amendment or Section 230 Communications Decency Act immunity. This creates direct liability pathway for organisations deploying AI chatbots.
Clinical Evidence: Psychiatrist Dr. Marlynn Wei warned AI chatbots' "limitations including hallucinations, sycophancy, lack of confidentiality, lack of clinical judgment, and lack of reality testing" create "mental health risks" particularly for youth users who increasingly turn to AI for emotional support.
Board Implications: Organisations deploying AI chatbots for customer service, HR, mental health applications, or any user interaction face product liability exposure. The Character.AI precedent means organisations cannot hide behind "it's just software" defences when AI systems cause documented harm.
Board Action: Immediate audit of customer-facing AI chatbots for psychological safety risks. Require: (1) crisis intervention protocols, (2) explicit warnings about AI limitations, (3) usage monitoring for vulnerable populations, (4) clear escalation to human oversight. Legal and risk teams must evaluate D&O insurance adequacy for AI-related harm claims.
Sources:
CNN, How AI shook the world in 2025 and what comes next, 30 Dec 2025 https://www.cnn.com/2025/12/30/tech/how-ai-changed-world-predictions-2026-vis
Stanford University Human-Centered AI, Most-Read: The Stories that Defined AI in 2025, 15 Dec 2025 https://hai.stanford.edu/news/most-read-the-stanford-hai-stories-that-defined-ai-in-2025
SOCIETAL RISK #2
AI-Driven Entry-Level Employment Displacement
Category: Economic & Environmental Sustainability | Priority: HIGH
Software developer employment (ages 22-25) declined 20% between 2022-2025, coinciding with AI coding tool adoption. Stanford Digital Economy Lab analysis of ADP payroll records - covering millions of workers across tens of thousands of firms - found AI-exposed occupations saw 13% relative employment decline for early-career workers. Customer service and accounting jobs showed similar patterns.
Talent Pipeline Disruption: Traditional organisational model (hire 10 junior developers, develop them into senior engineers over time) breaks when junior roles disappear. This creates succession risk: where do future technical leaders come from if entry-level training grounds vanish? Organisations face medium-term talent gaps as experienced developers retire without replacement pipeline.
Social Mobility Breakdown: Computer science graduates from Stanford - historically guaranteed employment - now face 6.1% unemployment. The traditional professional path (start with simple tasks, learn on the job, advance to complex work) collapses for entire cohorts
Not Self-Correcting: Market forces alone won't rebuild training pathways. Companies optimising for short-term productivity (2 senior engineers + AI vs. 10 junior engineers) don't internalise long-term costs of eliminating development pathways. This requires deliberate institutional intervention including retraining programs and apprenticeship models that preserve learning opportunities.
Key Sources:
ADN, "They graduated from Stanford: Due to AI, they can't find a job," 27 Dec 2025. https://www.adn.com/nation-world/2025/12/27/they-graduated-from-stanford-due-to-ai-they-cant-find-a-job/
Brynjolfsson, E., Chandar, A., & Chen, P., "Canaries in the Coal Mine? Six Facts about the Recent Labor Market Effects of AI," Stanford Digital Economy Lab, Aug 2025. https://digitaleconomy.stanford.edu/wp-content/uploads/2025/08/Canaries_BrynjolfssonChandarChen.pdf
EXECUTIVE AND BOARD ACTION IMPLICATIONS
1. AI Vendor Safety Framework Audit
Board committees responsible for technology risk and enterprise risk management should commission independent assessment of all critical AI vendors leveraging Future of Life Institute AI Safety Index criteria.
Actions:
Add safety framework requirements to AI vendor evaluation criteria. Require vendors to disclose risk thresholds, monitoring mechanisms, and governance structures.
Reference Future of Life Institute AI Safety Index (updated quarterly) as vendor assessment benchmark. If vendor scored D in existential safety, understand implications for your critical dependencies.
Include contractual provisions requiring vendors to notify if safety thresholds are breached and halt deployment if certain risk levels are reached.
Board Oversight: Establish quarterly vendor safety scorecard. For vendors scoring D in existential safety (all current frontier AI providers), understand implications for critical use cases and platform dependencies and develop contingency plans.
2. Security Posture: Treat AI Agents as Permanently Vulnerable
Inventory all deployed AI agents with email, document, or web access. Implement immediate containment protocols.
Actions:
Prohibit AI agent access to confidential repositories until architectural fixes available.
Conduct threat modeling for every current AI agent deployment. Document what data each agent accesses and what actions it can execute.
Require human confirmation for any AI agent action involving financial authority, data exports, or system modifications.
Implement audit logging for all AI agent activities and establish incident response protocols
Board Oversight: Risk committee should require monthly reporting on AI agent deployments with access to sensitive systems. Question: "What's our exposure if this agent is compromised?"
3. Product Liability Risk Assessment
For any customer-facing AI chatbot deployed or planned, conduct immediate psychological safety review following Character.AI product liability precedent.
Action:
Document crisis intervention protocols and human escalation triggers.
Implement usage monitoring for signs of user distress or overdependence.
Add explicit disclaimers about AI limitations and mental health resources.
Review product liability insurance coverage for AI-related harm claims.
Board Oversight: Legal and risk teams evaluate D&O insurance adequacy. Risk committee requires monthly reporting on AI chatbot deployments with user interaction risk.